

IBM Image Services
In the modern digital age, where information is paramount, efficient document management is key to success for businesses and organizations of all sizes. IBM Image Services, a robust and comprehensive solution designed to streamline document management, enhance workflow automation, and empower organizations to harness the full potential of their documents and images. In this blog, we’ll delve into the world of IBM Image Services, exploring its features, benefits, and the transformational impact it can have on your organization’s document handling processes.
The Foundation of IBM Image Services
At its core, IBM Image Services is a document management and imaging software solution. It provides a structured environment for capturing, storing, indexing, retrieving, and managing documents and images. Whether you’re dealing with paper-based documents or digital files, IBM Image Services offers a unified platform to bring order to the chaos of document management
Workflow Automation in Action
To illustrate the power of IBM Image Services, let’s walk through a real-world scenario
Imagine a large insurance company handling thousands of claims documents daily. With IBM Image Services, the company captures, indexes, and stores each claim document efficiently. These documents enter automated approval workflows, routing them to the appropriate claims adjusters and managers for review. Automated notifications keep everyone in the loop, and document versions are tracked to maintain data integrity
Additionally, compliance requirements dictate that certain claim documents must be retained for specific durations. IBM Image Services handles this effortlessly by applying retention policies, ensuring that documents are archived or disposed of in accordance with legal mandates

Key Features and Capabilities
Document Capture
IBM Image Services supports multiple methods of document capture, including scanning physical documents and importing electronic files. Its flexibility ensures that documents can be ingested from various sources, making it a versatile solution for organizations with diverse document types
Document Indexing
Efficient document indexing is a cornerstone of document management. With IBM Image Services, you can attach metadata and keywords to documents, making them easily searchable and retrievable. Customizable metadata fields allow you to categorize and organize documents according to your specific needs
Document Storage
IBM Image Services offers secure and scalable document storage. You can choose between on-premises or cloud-based storage options, ensuring that your documents are stored in a way that aligns with your organization’s infrastructure and security requirements.
Workflow Automation
Streamline your business processes with IBM Image Services’ workflow automation capabilities. Define and automate document-related workflows, including approval processes and document routing. This ensures that documents move seamlessly through your organization, improving efficiency and reducing manual intervention.
Document Security and Access Control
Protect your sensitive documents with robust security features. IBM Image Services provides user authentication, role-based access control, encryption, and auditing to ensure that only authorized personnel can access and modify documents.
Compliance and Records Management
IBM Image Services facilitates compliance by allowing you to define and enforce document retention policies, ensuring that you meet legal and industry-specific standards.
Integration
Seamlessly integrate IBM Image Services with other enterprise systems, such as Enterprise Content Management (ECM) systems, customer relationship management (CRM) software, and more. Integration enhances data exchange and ensures that your documents are accessible where and when you need them.
Extraction
Extracting documents and data from IBM Image Services can be a complex process that requires careful planning and execution. Below are the steps you can follow to extract content from IBM Image Services
Assessment and Preparation
Identify the scope: Determine the documents and data you need to extract. Understand the structure of your Image Services repository, including document classes, metadata, and folders.
Access Permissions
Ensure that you have the necessary permissions and access rights to retrieve data from IBM Image Services.
Data Extraction Method
Choose the appropriate method for data extraction based on your requirements and the capabilities of your Image Services installation
APIs
Image Services may provide APIs that allow programmatic access to content. Consult the Image Services documentation for details on available APIs and how to use them.
Database Queries
If APIs are not available or suitable, you may need to query the underlying Image Services database directly. This requires an understanding of the database schema and structure.
Export Tools
Some versions of Image Services may include export tools that facilitate data extraction. These tools often allow you to export documents and metadata in a structured format.
Metadata Retrieval
Consider whether you need to extract metadata associated with the documents. Metadata can include information such as document titles, dates, authors, and keywords. Extracting metadata can be valuable for organizing and searching the extracted data.
Content Retrieval
Extract the actual content of the documents. This could include images, text, or any other data stored within Image Services. Ensure that the content is retrieved in a format that is compatible with your target system or storage solution.
Data Transformation (if necessary)
Depending on your target system, you may need to transform the extracted data into a format suitable for ingestion. This may involve format conversion, data mapping, or other transformations.
Data Validation
During and after extraction, validate the data to ensure its accuracy, completeness, and integrity. Verify that all documents and associated metadata have been successfully retrieved.
Documentation
Thoroughly document the extraction process, including configurations, scripts or queries used, and any issues encountered. This documentation will be important for reference and auditing purposes.
Testing
Conduct extensive testing to ensure that the extracted data meets your requirements. Test document retrieval, metadata searches, and any other functionality that relies on the extracted data.
Backup
Before proceeding with the extraction, make sure to back up your Image Services data to prevent any data loss or corruption during the extraction process.
Secure Handling
Ensure that the extracted data is handled securely and in compliance with any relevant data protection regulations. Protect sensitive information and maintain data privacy.

Migration
Migration is the process of moving data, applications, and other resources from one system to another. It can be a complex process, but it is often necessary to improve the performance, security, or scalability of a system. There are a variety of migration methods available, depending on the type of data and applications being migrated. Some common migration methods include
Database migration
This involves migrating data from one database to another. This can be done using a variety of tools and methods, such as SQL queries, data pumps, and database connectors.
File migration
This involves migrating files from one system to another. This can be done using a variety of tools and methods, such as FTP, SCP, and file transfer software.
Application migration
his involves migrating applications from one system to another. This can be done using a variety of tools and methods, such as application migration tools, custom scripts, and manual processes.
The migration process steps
Planning
The first step is to plan the migration. This includes identifying the data and applications to be migrated, assessing the source and target systems, and developing a migration plan.
Preparation
The next step is to prepare for the migration. This includes setting up the target system and migrating the data and applications to the target system.
Testing
Once the data and applications have been migrated to the target system, you should test them to make sure that they are working properly. This includes testing the data and applications for functionality, performance, and security.
Cutover
The next step is to cutover from the source system to the target system. This involves switching over users and applications to the target system.
Post-migration
Once the cutover is complete, you should monitor the target system to make sure that it is operating properly. You should also provide support to users as they transition to the new system.
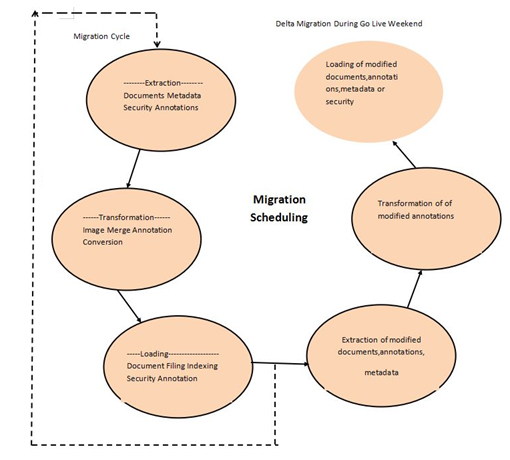
Extraction from image services and ingestion into FileNet P8
Migrating data or content from IBM Image Services to FileNet P8, another enterprise content management (ECM) system, typically involves several steps
1. Pre-Migration Planning
Inventory
Identify the content to be migrated, including documents, images, metadata, and associated information.
Mapping
Create a mapping between the data structures in IBM Image Services and FileNet P8 to ensure a smooth transition.
Migration Strategy
Define the migration strategy, including the migration approach (e.g., full migration or incremental migration), timing, and resources required.
2. Data Extraction from IBM Image Services
Use the provided APIs, tools, or scripting to extract content and metadata from IBM Image Services. The exact method depends on the version of IBM Image Services and your specific requirements.Ensure that the extracted content maintains its integrity, including any metadata associated with the documents.
3. Data Transformation and Preparation
Transform and prepare the extracted data to match the format and structure required by FileNet P8. This may involve data mapping, format conversion, and data cleansing. Ensure that the metadata mappings align with FileNet P8’s metadata schema.
4. Test Migration
Before performing the actual migration, conduct thorough testing in a controlled environment to validate the extraction, transformation, and loading (ETL) process. Verify that the data in FileNet P8 matches the data extracted from IBM Image Services.
5. Data Ingestion into FileNet P8
Utilize FileNet P8’s provided ingestion mechanisms or APIs to load the transformed data and content into the FileNet P8 repository. Ensure that the document security and access control settings are configured correctly during the ingestion process.
6. Post-Migration Validation
Verify the data’s integrity, completeness, and accuracy in FileNet P8. Conduct tests to ensure that users can retrieve and work with documents effectively within the FileNet P8 environment.
7. Decommission IBM Image Services
Once you are confident that the migration was successful and that all required content is available in FileNet P8, you can proceed with decommissioning IBM Image Services. Ensure proper backup and archival of data from IBM Image Services for compliance and historical purposes.
8. User Training and Transition
Train users and administrators on how to access and work with documents within the FileNet P8 system. Communicate the migration’s completion and any changes in document management procedures.
9. Monitoring and Maintenance
Continuously monitor the FileNet P8 system to ensure its performance and availability. Establish maintenance procedures and periodic reviews to address any issues or improvements.
10. Documentation
Maintain detailed documentation of the entire migration process, including configurations, mappings, and any issues encountered. Document any post-migration tasks and ongoing maintenance procedures.